2025年5月7日�����,Jing-Xian Wang等人在《Front Cardiovasc Med》雜志上發(fā)表了一篇題為《Machine learning algorithms to predict heart failure with preserved ejection fraction among patients with premature myocardial infarction》的文章�����。 早發(fā)性心肌梗死(PMI)患者射血分數(shù)保留的心力衰竭(HFpEF)是影響長期預后的關鍵因素�����。本研究旨在開發(fā)一種基于機器學習算法的模型�,該模型可以及早快速預測PMI患者發(fā)生院內HFpEF的風險。
HFpEF在急性心肌梗死(AMI)患者中占比逐年上升�,尤其在年輕人群中預后較差,但其預測模型研究仍存在空白�。因此本研究聚焦于比較不同機器學習模型的性能,篩選關鍵預測因子�����,并構建可解釋的臨床決策支持工具�����,從而為高風險患者的個體化干預提供依據(jù)����,降低HFpEF發(fā)病率并改善長期預后。
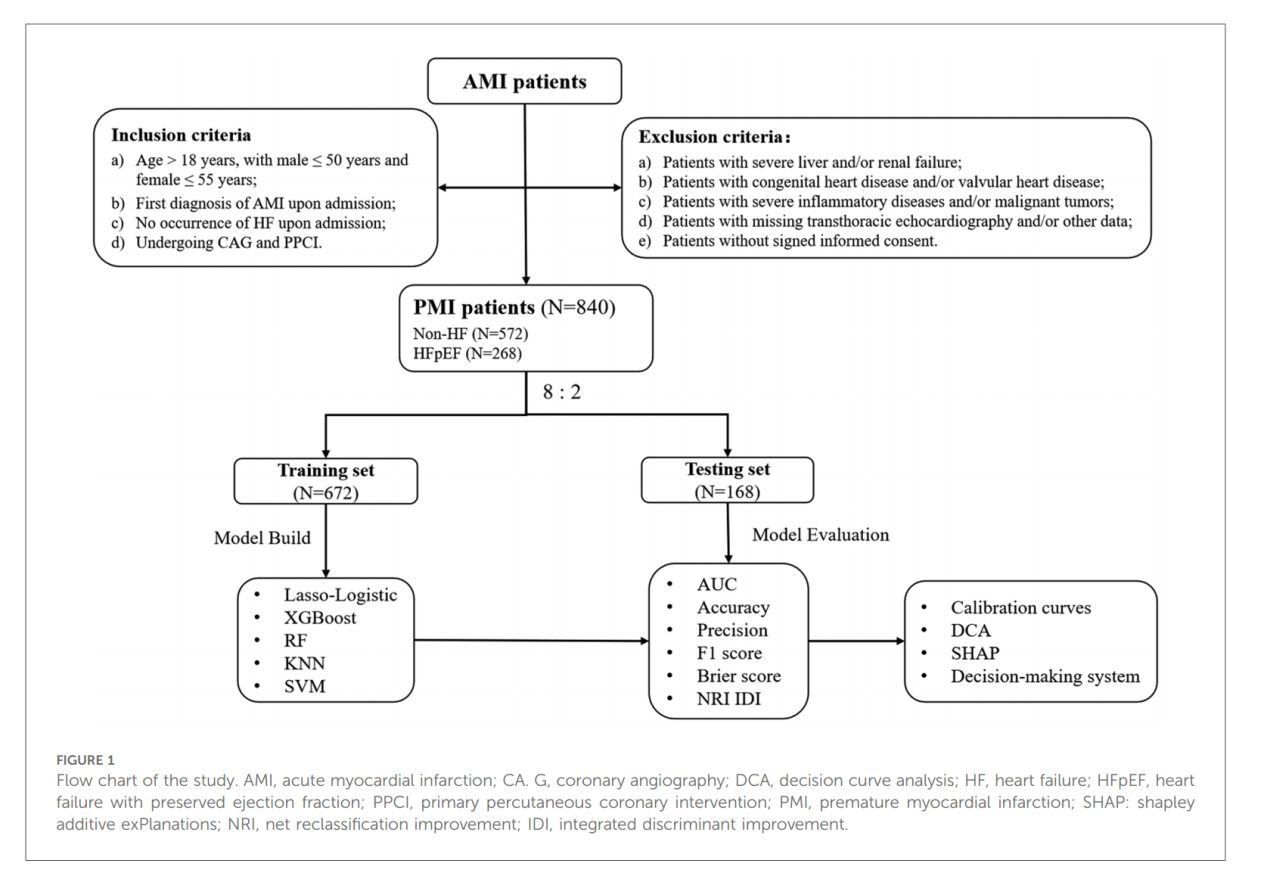
本研究數(shù)據(jù)來源于2017年1月至2022年12月天津胸科醫(yī)院的前瞻性單中心隊列�����,納入840例AMI的患者�����。納入標準包括:符合PMI年齡標準(年齡>18歲���,且男性≤50歲或女性≤55歲)�����;首次診斷為AMI����;入院時無心力衰竭�、接受冠狀動脈造影(CAG)及直接經(jīng)皮冠狀動脈介入治療(PPCI)。排除嚴重肝腎功能衰竭�、先天性或瓣膜性心臟病、嚴重炎癥性疾病�、惡性腫瘤、關鍵檢查數(shù)據(jù)缺失及未簽署知情同意書的病例����。
收集數(shù)據(jù)包括人口學特征即年齡��、性別���、BMI�����、吸煙與飲酒史����、冠心病家族史(CAD)、既往病史����、AMI類型);入院生命體征���;實驗室檢查��、冠狀動脈造影(CAG)及經(jīng)胸超聲心動圖(TTE)參數(shù)���;實驗室指標如炎癥比值CLR(C反應蛋白與淋巴細胞比值)和MLR(單核細胞與淋巴細胞比值)、冠脈造影結果(含SYNTAX評分)�����、超聲心動圖參數(shù)及用藥信息�。所有數(shù)據(jù)均通過標準化電子病歷系統(tǒng)采集以確保一致性。研究流程詳見圖1�����。
本研究基于Riley等人提出的pmsampsize準則確定最小樣本量為298例����。數(shù)據(jù)缺失率低于5%的變量采用中位數(shù)填補連續(xù)變量缺失值,分類變量使用多重插補��。數(shù)據(jù)集按8:2比例隨機分為訓練集(80%)和測試集(20%)���,訓練集內采用五折交叉驗證�。除年齡經(jīng)最小-最大標準化外��,其余連續(xù)變量均按臨床參考范圍(如BMI≥24 kg/m2)���、指南或中位數(shù)如總膽汁酸(TBA)�����、CLR、MLR轉換為分類變量�。針對HFpEF樣本量不足問題,采用SMOTE技術平衡數(shù)據(jù)(k=5�����,過采樣比=1)。構建五種機器學習模型����,包括套索邏輯回歸(Lasso-Logistic)、極限梯度提升(XGBoost)�����、隨機森林(RF)�、K近鄰(KNN)、支持向量機(SVM)模型預測院內HFpEF的發(fā)生���。通過方差膨脹因子(VIF>10)排除多重共線性變量后����,Lasso回歸篩選出12個關鍵預測因子并構建邏輯模型�����;其余模型基于全變量訓練后�����,選取特征重要性排名前10的變量重新建模。模型優(yōu)化采用自動調參策略��,結合五折交叉驗證評估泛化性能�,最終通過測試集計算AUC、準確率����、F1分數(shù)及Brier分數(shù)進行驗證。使用凈重新分類改進指數(shù)(NRI)和綜合判別改進指數(shù)(IDI)量化模型預測能力的提升�,并基于性能對比選定最優(yōu)模型。模型解釋采用SHAP值可視化變量貢獻度�,校準曲線評估預測概率與實際概率的一致性,決策曲線分析(DCA)量化不同閾值下的臨床凈獲益�。
研究人群基線特征如表1所示����,共納入840例患者(HFpEF組268例,非HF組572例)�����,中位年齡42[38-44]歲��,男性占91.0%�。組間比較顯示,HFpEF組女性比例顯著高于非HF組(15.7% vs. 5.9%�����,P<0.001)���,年齡更大(42[39-45] vs. 41[37-44]歲�����,P=0.001)��,肥胖(BMI≥24 kg/m2:82.5% vs. 74.5%�,P=0.013)和高血壓(56.3% vs. 45.8%����,P=0.006)比例更高。實驗室指標方面�,HFpEF組炎癥標志物(CRP>5.0 mg/L:63.4% vs. 43.5%;MLR>0.3:65.7% vs. 42.7%�,均P<0.001)及腦鈉肽(BNP)>100 pg/ml比例(91.0% vs. 62.4%,P<0.001)顯著升高�。冠脈造影顯示HFpEF組SYNTAX評分>14.5的比例更高(64.2% vs. 43.0%,P<0.001),提示更嚴重的冠脈病變�。綜上,HFpEF患者具有年齡較大�、合并癥負擔更重、心血管功能障礙更顯著的特征�。訓練集與測試集的基線特征及連續(xù)變量描述性統(tǒng)計分別見補充表S2和S3。

研究將840例患者按8:2比例隨機劃分為訓練集(672例)和測試集(168例)��,所有預測變量的方差膨脹因子(VIF)均<5��,表明多重共線性問題不顯著����。基于Lasso回歸的變量篩選(圖2A-B)從全變量集中識別出12個關鍵預測因子����,包括女性、高血壓��、STEMI����、BMI≥24 kg/m2、SYNTAX評分>14.5�、入院心率(HR)>75次/分���、中性粒細胞百分比(NEU%)>75%、紅細胞壓積(HCT)<45%���、心肌肌鈣蛋白T(cTnT)>1.44 ng/L、MLR>0.3����、CLR>2.83及BNP>100 pg/ml。經(jīng)多因素Logistic回歸進一步篩選后�,最終模型保留8個變量:女性、BMI≥24 kg/m2���、SYNTAX評分>14.5����、HR>75次/分��、HCT<45%�����、MLR>0.3�、CLR>2.83及BNP>100 pg/ml���。RF、XGBoost�����、KNN和SVM模型經(jīng)全變量訓練后�����,基于特征重要性排名選取前10個變量重新建模����。各模型的特征重要性排序分別展示于圖2C-G中,其中XGBoost模型的關鍵變量包括BNP水平�����、SYNTAX評分�����、年齡��、炎癥比值等(如圖2D)�。

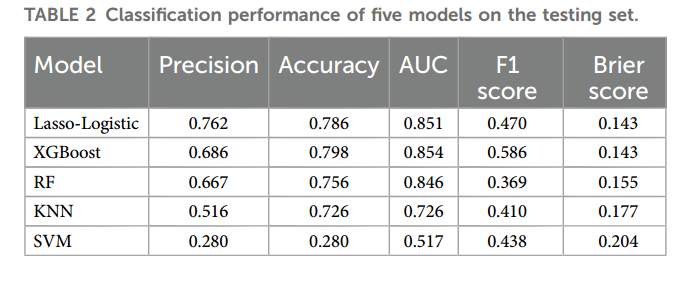
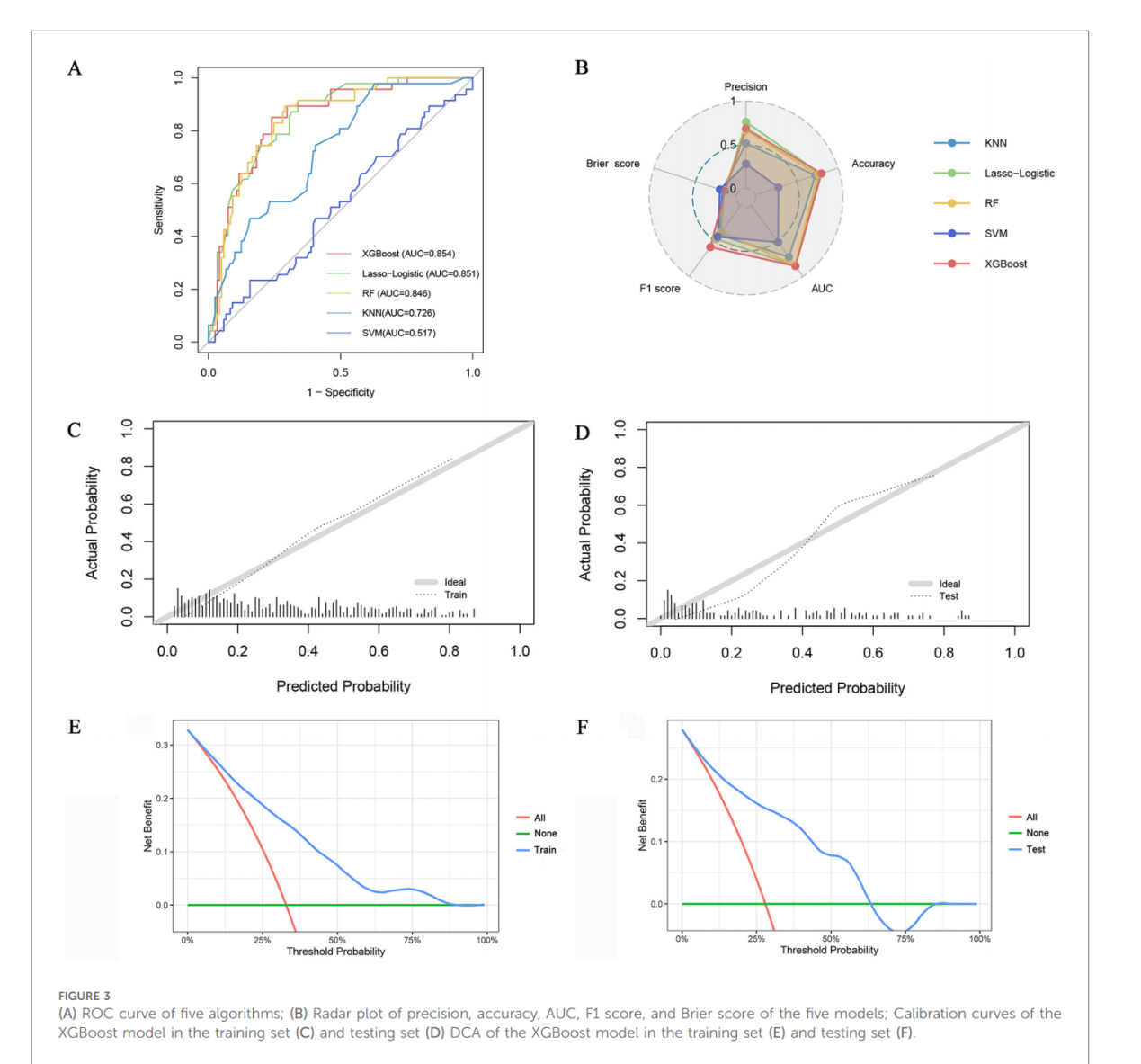
各模型在測試集的分類性能比較如表2及圖3A-B所示��。五種機器學習模型的AUC范圍為0.517(SVM)至0.854(XGBoost)����,其中XGBoost的AUC�、準確率(0.798)及F1分數(shù)(0.586)均為最優(yōu),Brier分數(shù)(0.143)與Lasso-Logistic相當����。雷達圖(圖3B)綜合顯示XGBoost在多數(shù)指標上表現(xiàn)突出��。補充圖S1表明�����,SMOTE技術有效平衡了訓練集類別分布����,提升XGBoost與KNN的F1分數(shù)及AUC,但SVM性能未改善���。
通過凈重新分類改進指數(shù)(NRI)和綜合判別改進指數(shù)(IDI)分析���,XGBoost相比其他模型預測能力顯著更優(yōu)(均P<0.05)��。例如����,與Lasso-Logistic相比��,NRI=0.149(95%CI:0.008-0.290)��,IDI=0.049(95%CI:0.008-0.091)����;與SVM相比,NRI=0.428(95%CI:0.277-0.579)�,IDI=0.227(95%CI:0.175-0.279)(補充表S5)。校準曲線顯示XGBoost預測概率與實際概率高度一致(圖3C-D)����,決策曲線分析(圖3E-F)證實其在廣泛閾值范圍內具有臨床凈獲益。綜上�����,XGBoost因綜合性能最優(yōu)被選為最終模型����。
XGBoost模型變量的重要性排序顯示BNP >100 pg/ml是影響PMI患者院內HFpEF發(fā)生的最重要特征�����。此外�����,SYNTAX評分> 14.5����、年齡��、MLR >0.3�、HCT <45%���、HR >75 bpm��、身體質量指數(shù)≥24 kg/m2���、CLR >2.83、高血壓�����、Fg ≥4 g/L也是預測HFpEF的重要變量(圖2D)。圖4A和補充表S6顯示����,上述變量是PMI患者院內HFpEF的風險因素。
視覺預測系統(tǒng)包括用于輸入患者變量(例如���,年齡��、高血壓狀態(tài))的輸入界面(左)和顯示預測概率(上)和解釋模型決策的個性化SHAP圖(下)的輸出界面(右)�。在圖4B中�����,系統(tǒng)根據(jù)臨床輸入預測PMI患者發(fā)生HFpEF的概率為65.5%�。該系統(tǒng)向公眾開放https://hfpefpmi.shinyapps.io/apppredict/.
基于XGBoost算法建立的可解釋預測模型可以準確預測PMI患者的院內HFpEF風險�,該模型有望通過為PMI患者提供及時、優(yōu)先和精確的干預措施來幫助臨床醫(yī)生做出決策��,最終降低HFpEF的發(fā)生率并改善長期預后�����。
上一篇:05.19-05.25 臨床預測模型研究頂刊快報
下一篇:構建基于機器學習的孕中期流產(chǎn)風險預測模型